翻译 cncf 原文:
https://www.cncf.io/blog/2026/03/17/when-kubernetes-restarts-your-pod-and-when-it-doesnt/
本文基于 Kubernetes 1.35 正式版验证,配套代码仓库:
github.com/opscart/k8s-pod-restart-mechanics
很多工程师说 “Pod 重启了”,实际指代四种完全不同的行为。概念混淆会直接导致错误的运维手册与故障处理决策。
术语 | Pod UID 是否变化 | Pod IP 是否变化 | 重启计数 |
容器重启(同一 Pod 内进程重启) | 否 | 否 | +1 |
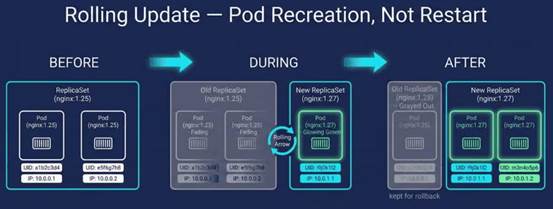
Pod 重建(滚动更新、节点排空) | 是 | 是 | 重置为 0 |
原地扩容(1.35 正式版)— CPU | 否 | 否 | 0 |
原地扩容(1.35 正式版)— 内存(RestartContainer 策略) | 否 | 否 | +1 |
实用判断法:Pod UID 变了 = 重建,不是容器重启,重启计数归零;UID 没变 = 同一个 Pod 对象,仅内部容器进程重启。
kubelet 只监控 Pod 规范(Pod Spec),不监控 ConfigMap、Secret、Istio CRD 等资源。只要 Pod Spec 没变更,kubelet 就不会触发任何动作——这是生产中配置更新不生效的最核心原因。
变更准入 Webhook 仅能在 Pod 创建时修改 Spec,创建后无法触发容器重启。
变更类型 | 容器重启? | Pod 重建? | 是否自动? |
容器镜像 | 是 | 是 | 是(Deployment 控制器) |
环境变量(任意来源) | 是 | 否 | 手动滚动发布 |
ConfigMap—卷挂载 | 应用决定 | 否 | 部分自动(应用需监听 inotify) |
ConfigMap—envFrom | 是 | 否 | 手动滚动发布 |
Secret—卷挂载 | 应用决定 | 否 | 部分自动(应用需监听 inotify) |
Secret—envFrom | 是 | 否 | 手动滚动发布 |
projected ServiceAccount 令牌 | 从不 | 否 | 是(kubelet 自动轮转) |
CPU 扩容(K8s 1.35+) | 从不 | 否 | 手动补丁 |
内存扩容(K8s 1.35+) | 依 resizePolicy | 否 | 手动补丁 |
Istio VirtualService/DestinationRule | 从不 | 否 | 是(xDS 推送) |
NetworkPolicy | 从不 | 否 | 是(CNI 代理) |
Service 端口 | 从不 | 否 | 是(kube-proxy) |
RBAC | 从不 | 否 | 是(API Server) |
节点排空 / 驱逐 | 是 | 是 | 自动 |
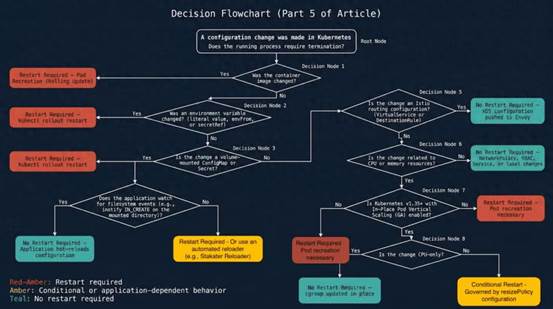
决策图
环境变量模式 Vs 卷挂载模式
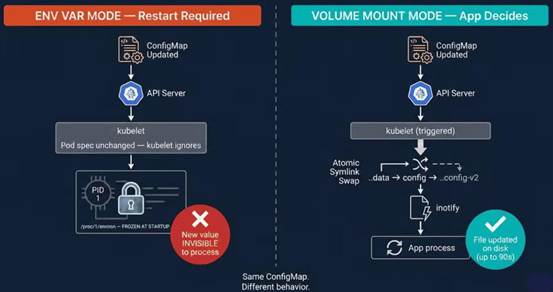
内核在 execve() 时将环境变量复制到 /proc/<pid>/environ,这段内存归进程独有,外部系统无法修改。更新 ConfigMap 但 Pod Spec 不变,kubelet 无动作,进程永久使用旧值。
kubelet 通过原子符号链接替换同步,而非直接写文件:
/etc/config/
├── ..2025_12_19_11_30_00/ ← 新数据目录(kubelet 创建)
│ └── APP_COLOR ← "red"
├── ..data ─────────────────▶ ..2025_12_19_11_30_00/ ← 原子替换符号链接
└── APP_COLOR ──────────────▶ ..data/APP_COLOR
符号链接替换触发 ..data 的 IN_CREATE 事件,而非文件的 IN_MODIFY。监听文件 IN_MODIFY 的应用会完全错过更新——这就是 Nginx 不自动重载 ConfigMap 的原因。
实验结果
ConfigMap updated: APP_COLOR blue → red
Pod A (env var): APP_COLOR=blue ← frozen, restart count: 0
Pod B (volume mount): APP_COLOR=red ← auto-synced, restart count: 0
正确监听方式:监听目录,而非文件
watcher.Add(filepath.Dir(configPath)) // 监听 /etc/config/,捕获 IN_CREATE
// watcher.Add(configPath) // 完全错过符号链接替换
forevent := range watcher.Events {
ifevent.Op&fsnotify.Create == fsnotify.Create {
reloadConfig()
}
}
2. ImagePullBackOff:旧 Pod 保持运行,新 Pod 拉取镜像失败,旧 Pod 直到新 Pod 健康才会被销毁。
Old pod: Running ← Kubernetes keeps it alive
New pod: ImagePullBackOff ← stuck, old pod never killed untilnew one is healthy
3. CrashLoopBackOff:同一 Pod,重启计数持续攀升,UID 不变。
Pod UID: aaa-bbb ← UNCHANGED
Restart count: 0 → 1 → 2 → 3 ← same pod object, container crashing
诊断规则:重启计数上升 + UID 不变 = 崩溃循环;重启计数为 0 + 新 UID = 滚动更新。
StatefulSet 镜像更新同样重建 Pod,但保留序号标识(pod-0、pod-1)与 PVC 绑定,容器重启语义与 Deployment 一致。
K8s 1.35 正式发布 Pod 原地扩容,无需重建 Pod,UID、IP 保持不变,依赖 containerd 1.7+ 与 Linux cgroups v2。
容器行为由 resizePolicy 控制:
resizePolicy:
- resourceName: cpu
restartPolicy: NotRequired # 仅更新 cgroup 配额,进程无感知
- resourceName: memory
restartPolicy: RestartContainer # 同一 Pod 内重启容器
CPUresize 200m → 500m (NotRequired):
UID: d7c99204 IP: 10.244.0.7 Restarts: 0 ← allunchanged
Memoryresize 256Mi → 512Mi (RestartContainer):
UID: d7c99204 IP: 10.244.0.7 Restarts: 1
↑ samepod ↑ sameIP ↑ ourpolicychoice, notK8sforcingit
重要:内存默认 resizePolicy 为 NotRequired,省略会导致 cgroup 静默更新但 JVM 堆大小不变,必须显式声明内存扩容策略。
执行命令:
kubectl patch pod my-pod -n my-namespace \
--subresource resize \
-p '{"spec":{"containers":[{"name":"app","resources":{
"requests":{"cpu":"250m","memory":"128Mi"},
"limits":{"cpu":"500m","memory":"256Mi"}
}}]}}'
xDS 是 Istio 中用于路由配置推送的核心机制,本质是 Istiod(Istio 控制平面)与 Envoy 边车(Sidecar)之间的配置同步协议。
Istio 路由规则变更从不触发容器重启。Istiod 与 Envoy 边车保持 gRPC 长连接,路由更新通过内存交换毫秒级推送,不触及 Pod、不写入文件。
Four pods. Three routing changes:
100% v1 → 80/20 canary → 100% v2
Restart counts: BEFORE 0 0 0 0 / AFTER 0 0 0 0
Pod ages: unchanged throughout all three changes.
实验验证:三次路由切换,所有 Pod 重启数始终为 0,Pod 运行时长无变化。
通过环境变量使用 ConfigMap/Secret 时,每次更新都需手动执行 kubectl rollout restart。
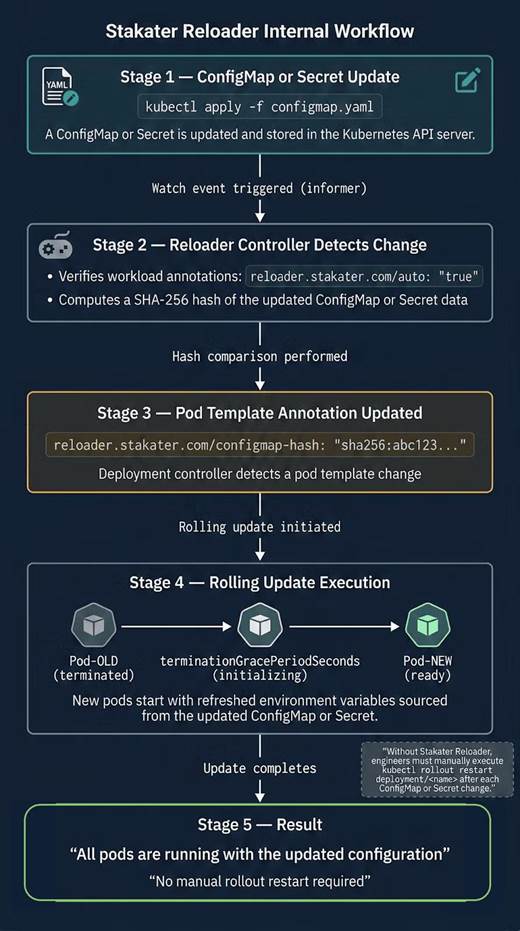
Stakater Reloader 是一款 Kubernetes 辅助工具,核心作用是监听 ConfigMap、Secret 的变更事件,自动触发工作负载(如 Deployment)的滚动重启,无需手动执行 kubectl rollout restart
Reloader 监听 Kubernetes 事件,自动触发滚动重启。
使用方式:
metadata:
annotations:
reloader.stakater.com/auto: "true"
生产注意:Helm 默认 watchGlobally=false,仅监听自身命名空间,需全局安装:
helm install reloader stakater/reloader \
--namespace reloader \
--set reloader.watchGlobally=true
热重载不代表更安全,存在两类隐蔽故障:
缓解:原子替换前校验配置。
2. Envoy 静默拒绝 xDS 推送:路由规则引用未同步集群,Envoy 保留旧规则,无 Pod 事件。
缓解:监控 pilot_xds_push_errors,使用 istioctl proxy-status。
# 1. 区分容器重启 vs Pod 重建(检查 UID)
kubectl get pod <pod> -o custom-columns=\
"NAME:.metadata.name,UID:.metadata.uid,IP:.status.podIP,RESTARTS:.status.containerStatuses[0].restartCount"
# 2. 查看 Pod 事件
kubectl describe pod <pod> | grep -A 20 "Events:"
# 3. 查看原地扩容状态
kubectl get pod <pod> -o jsonpath='{.status.resize}'
容器重启直接透明,故障即时暴露;热重载保障可用性,但故障隐蔽延迟。两种方案无优劣,需有意识选择。
运维的核心不是更快自动化重启,而是精准判断:仅在进程必须重启时触发,其余场景用非重启机制完成变更。
全文完
 京公网安备 11010802036102号北京金支点技术服务有限公司保留所有权利 | Copyright © 2005-2026 Beijing Golden Point Outsourcing Service Co., Ltd. All Rights Reserved.
京公网安备 11010802036102号北京金支点技术服务有限公司保留所有权利 | Copyright © 2005-2026 Beijing Golden Point Outsourcing Service Co., Ltd. All Rights Reserved.