1 .算力时代,GPU开拓新场景
广义上讲只要能够运行人工智能算法的芯片都叫作 AI 芯片。但是通常意义上的 AI 芯片指的是针对人工智能算法做了特殊加速设计的芯片。AI芯片也被称为AI加速器或计算卡,即专门用于处理人工智能应用中的大量计算任务的模块(其他非计算任务仍由CPU负责)。
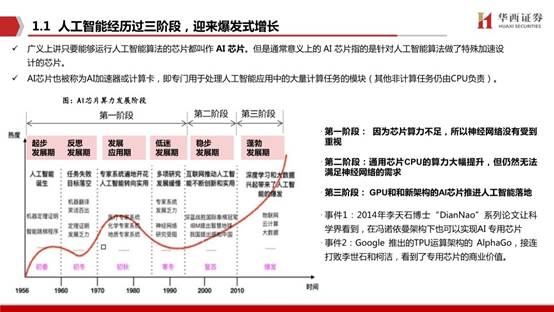
第一阶段: 因为芯片算力不足,所以神经网络没有受到重视;
第二阶段:通用芯片CPU的算力大幅提升,但仍然无法满足神经网络的需求;
第三阶段: GPU和和新架构的AI芯片推进人工智能落地。
GPT-3模型目前已入选了《麻省理工科技评论》2021年“十大突破性技术。 GPT-3的模型使用的最大数据集在处理前容量达到了45TB。根据 OpenAI的算力统计单位petaflops/s-days,训练AlphaGoZero需要1800-2000pfs-day,而GPT-3用了3640pfs-day。
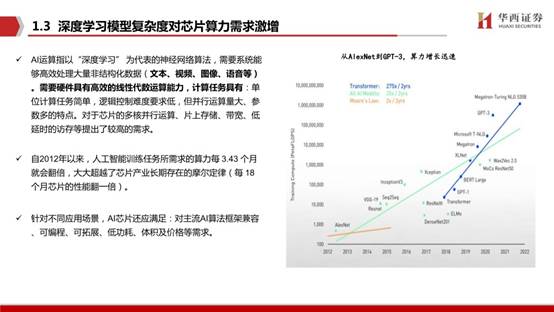
AI运算指以“深度学习” 为代表的神经网络算法,需要系统能够高效处理大量非结构化数据(文本、视频、图像、语音等)。需要硬件具有高效的线性代数运算能力,计算任务具有:单位计算任务简单,逻辑控制难度要求低,但并行运算量大、参数多的特点。对于芯片的多核并行运算、片上存储、带宽、低延时的访存等提出了较高的需求。
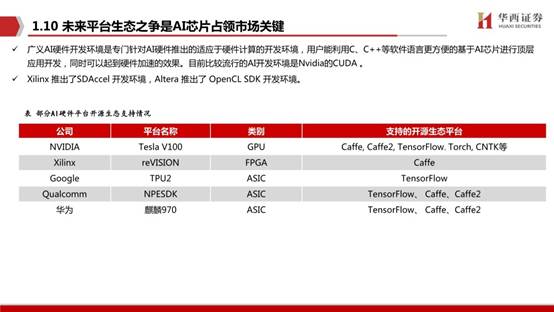
自2012年以来,人工智能训练任务所需求的算力每 3.43个月就会翻倍,大大超越了芯片产业长期存在的摩尔定律(每 18个月芯片的性能翻一倍)。针对不同应用场景,AI芯片还应满足:对主流AI算法框架兼容、可编程、可拓展、低功耗、体积及价格等需求。
根据机器学习算法步骤,可分为训练(training)芯片和推断(inference)芯片。训练芯片主要是指通过大量的数据输入,构建复杂的深度神经网络模型的一种AI芯片,运算能力较强。推断芯片主要是指利用训练出来的模型加载数据,计算“推理”出各种结论的一种AI芯片,侧重考虑单位能耗算力、时延、成本等性能。
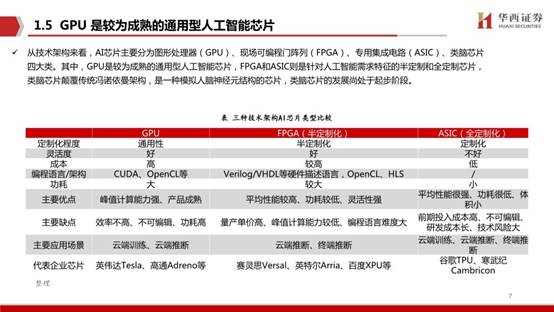
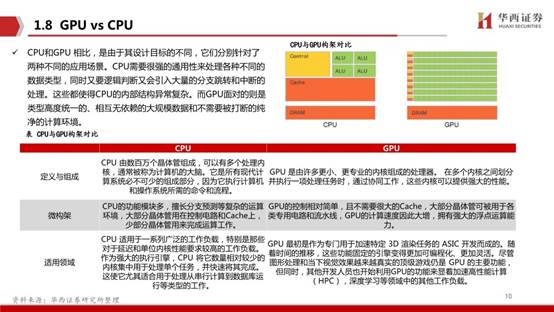
从技术架构来看,AI芯片主要分为图形处理器(GPU)、现场可编程门阵列(FPGA)、专用集成电路(ASIC)、类脑芯片四大类。其中,GPU是较为成熟的通用型人工智能芯片,FPGA和ASIC则是针对人工智能需求特征的半定制和全定制芯片,类脑芯片颠覆传统冯诺依曼架构,是一种模拟人脑神经元结构的芯片,类脑芯片的发展尚处于起步阶段。
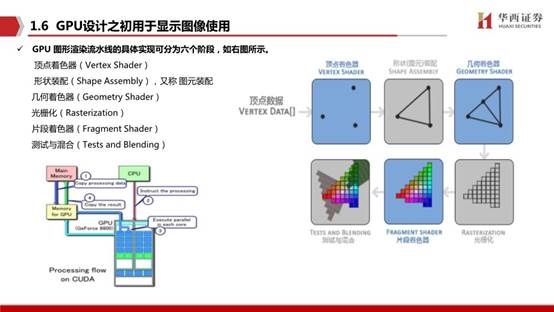
GPU(图形处理器)又称显示核心、显卡、视觉处理器、显示芯片或绘图芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上运行绘图运算工作的微处理器。GPU使显卡减少对CPU的依赖,并分担部分原本是由CPU所担当的工作,尤其是在进行三维绘图运算时,功效更加明显。图形处理器所采用的核心技术有硬件坐标转换与光源、立体环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等。GPU是一种特殊类型的处理器,具有数百或数千个内核,经过优化,可并行运行大量计算。虽然GPU在游戏中以3D渲染而闻名,但它们对运行分析、深度学习和机器学习算法尤其有用。
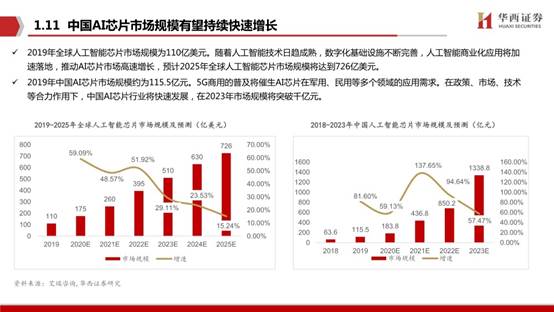
2019年全球人工智能芯片市场规模为110亿美元。随着人工智能技术日趋成熟,数字化基础设施不断完善,人工智能商业化应用将加速落地,推动AI芯片市场高速增长,预计2025年全球人工智能芯片市场规模将达到726亿美元。2019年中国AI芯片市场规模约为115.5亿元。5G商用的普及将催生AI芯片在军用、民用等多个领域的应用需求。在政策、市场、技术等合力作用下,中国AI芯片行业将快速发展,在2023年市场规模将突破千亿元。
2 .GPU 下游三大应用市场
GPU其实是由硬件实现的一组图形函数的集合,这些函数主要用于绘制各种图形所需要的运算。这些和像素,光影处理,3D坐标变换等相关的运算由GPU硬件加速来实现。图形运算的特点是大量同类型数据的密集运算——如图形数据的矩阵运算,GPU的微架构就是面向适合于矩阵类型的数值计算而设计的,大量重复设计的计算单元,这类计算可以分成众多独立的数值计算——大量数值运算的线程,而且数据之间没有像程序执行的那种逻辑关联性。
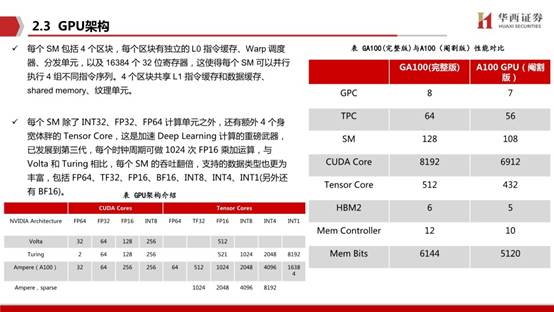
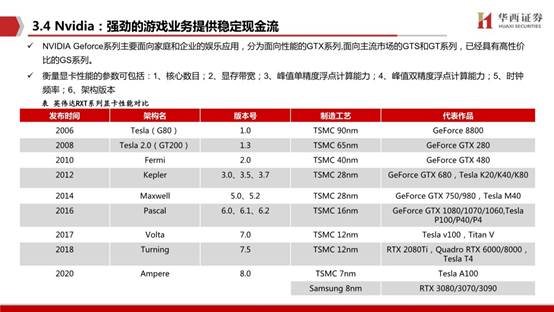
GPU微架构的设计研发是非常重要的,先进优秀的微架构对GPU实际性能的提升是至关重要的。目前市面上有非常丰富GPU微架构,比如Pascal、Volta、Turing(图灵)、Ampere(安培),分别发布于 2016 年、2017 年、2018年和2020年,代表着英伟达 GPU 的最高工艺水平。
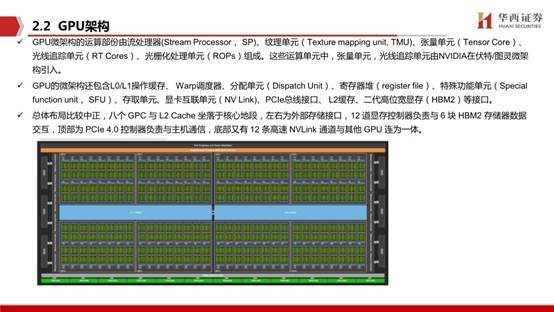
GPU微架构的运算部份由流处理器(Stream Processor, SP)、纹理单元(Texture mapping unit, TMU)、张量单元(Tensor Core)、光线追踪单元(RT Cores)、光栅化处理单元(ROPs)组成。这些运算单元中,张量单元,光线追踪单元由NVIDIA在伏特/图灵微架构引入。GPU的微架构还包含L0/L1操作缓存、 Warp调度器、分配单元(Dispatch Unit)、寄存器堆(register file)、特殊功能单元(Specialfunction unit, SFU)、存取单元、显卡互联单元(NV Link)、PCIe总线接口、 L2缓存、二代高位宽显存(HBM2)等接口。
总体布局比较中正,八个 GPC 与 L2 Cache 坐落于核心地段,左右为外部存储接口,12 道显存控制器负责与 6 块 HBM2 存储器数据交互,顶部为 PCIe 4.0 控制器负责与主机通信,底部又有 12 条高速 NVLink 通道与其他 GPU 连为一体。
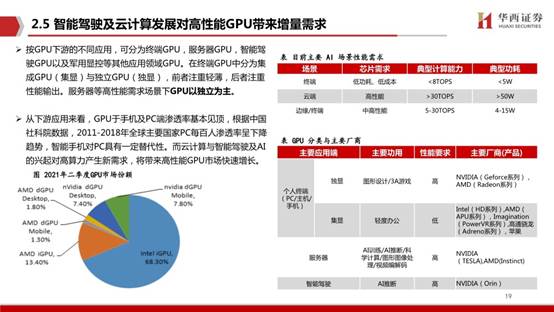
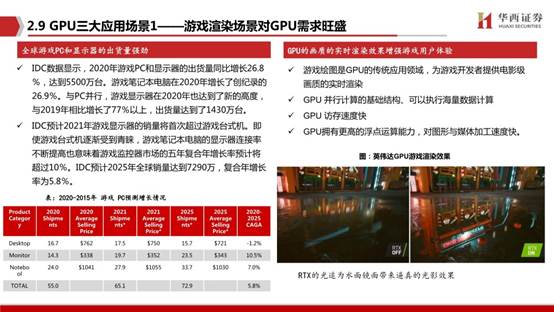
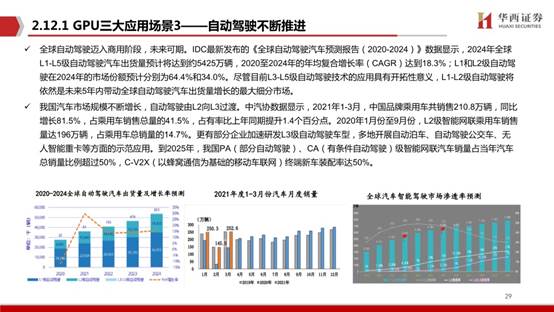
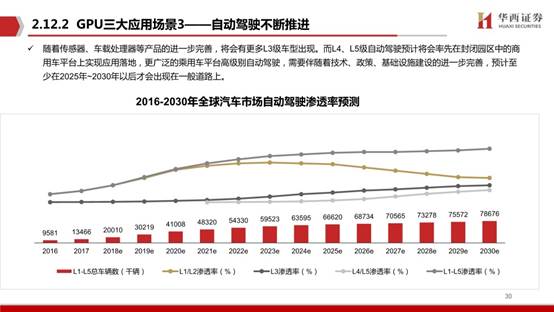
按GPU下游的不同应用,可分为终端GPU,服务器GPU,智能驾驶GPU以及军用显控等其他应用领域GPU。在终端GPU中分为集成GPU(集显)与独立GPU(独显),前者注重轻薄,后者注重性能输出。服务器等高性能需求场景下GPU以独立为主。
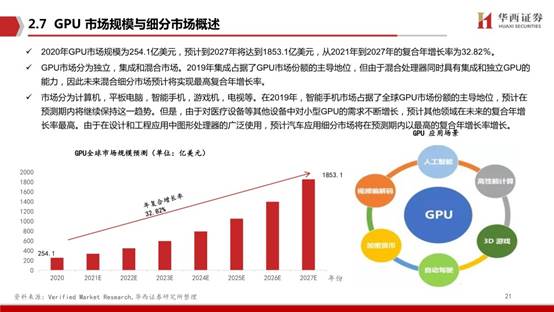
2020年GPU市场规模为254.1亿美元,预计到2027年将达到1853.1亿美元,从2021年到2027年的复合年增长率为32.82%。GPU市场分为独立,集成和混合市场。2019年集成占据了GPU市场份额的主导地位,但由于混合处理器同时具有集成和独立GPU的能力,因此未来混合细分市场预计将实现最高复合年增长率。
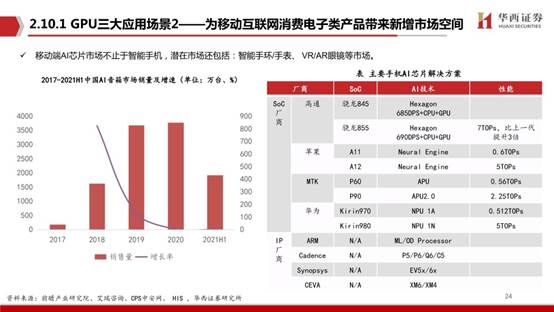
市场分为计算机,平板电脑,智能手机,游戏机,电视等。在2019年,智能手机市场占据了全球GPU市场份额的主导地位,预计在预测期内将继续保持这一趋势。但是,由于对医疗设备等其他设备中对小型GPU的需求不断增长,预计其他领域在未来的复合年增长率最高。由于在设计和工程应用中图形处理器的广泛使用,预计汽车应用细分市场将在预测期内以最高的复合年增长率增长。
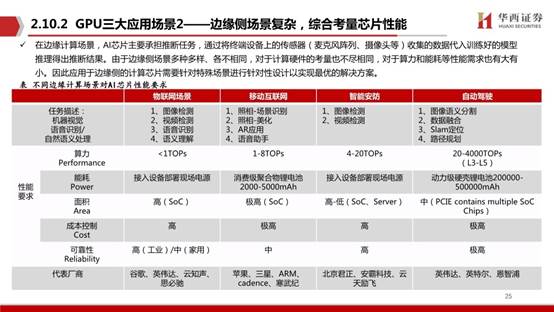
在边缘计算场景,AI芯片主要承担推断任务,通过将终端设备上的传感器(麦克风阵列、摄像头等)收集的数据代入训练好的模型推理得出推断结果。由于边缘侧场景多种多样、各不相同,对于计算硬件的考量也不尽相同,对于算力和能耗等性能需求也有大有小。因此应用于边缘侧的计算芯片需要针对特殊场景进行针对性设计以实现最优的解决方案。
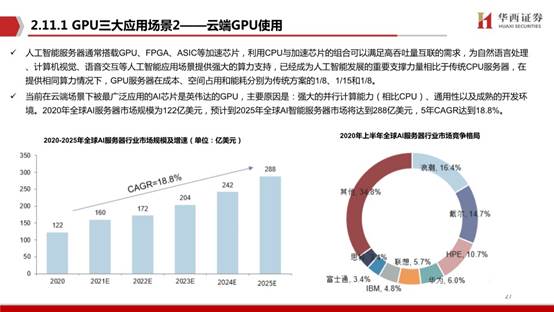
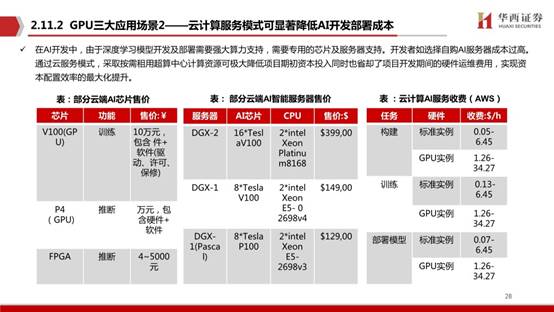
人工智能服务器通常搭载GPU、FPGA、ASIC等加速芯片,利用CPU与加速芯片的组合可以满足高吞吐量互联的需求,为自然语言处理、计算机视觉、语音交互等人工智能应用场景提供强大的算力支持,已经成为人工智能发展的重要支撑力量相比于传统CPU服务器,在提供相同算力情况下,GPU服务器在成本、空间占用和能耗分别为传统方案的1/8、1/15和1/8。
当前在云端场景下被最广泛应用的AI芯片是英伟达的GPU,主要原因是:强大的并行计算能力(相比CPU)、通用性以及成熟的开发环境。2020年全球AI服务器市场规模为122亿美元,预计到2025年全球AI智能服务器市场将达到288亿美元,5年CAGR达到18.8%。
3 .海外GPU巨头Nvidia
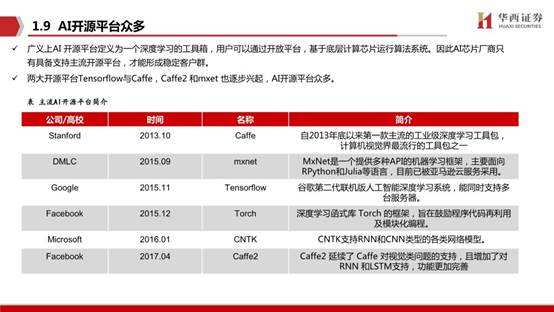
GPU通用计算方面的标准目前有OpenCL、CUDA、AMD APP、DirectCompute。其中OpenCL、DirectCompute、AMD APP(基于开放型标准OpenCL开发)是开放标准,CUDA是私有标准。(报告来源:未来智库)
2006年,公司推出CUDA 软件推展,推动GPU 向通用计算转变,之后不断强化通用系统生态构建。为开发者提供了丰富的开发软件站SDK、支持现有的大部分机器学习、深度学习开发框架。推出的cuDNN、TensorRT、DeepStream 等优化的软件也为 GPU 通用计算提供加速 。
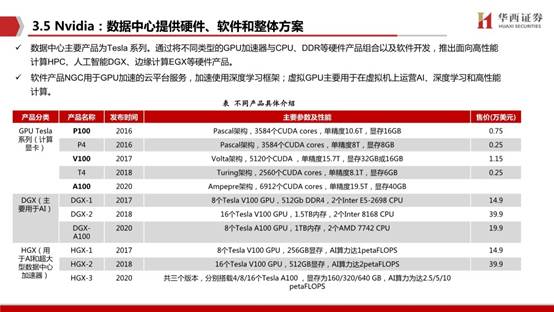
NVIDIA Geforce系列主要面向家庭和企业的娱乐应用,分为面向性能的GTX系列,面向主流市场的GTS和GT系列,已经具有高性价比的GS系列。数据中心主要产品为Tesla 系列。通过将不同类型的GPU加速器与CPU、DDR等硬件产品组合以及软件开发,推出面向高性能计算HPC、人工智能DGX、边缘计算EGX等硬件产品。软件产品NGC用于GPU加速的云平台服务,加速使用深度学习框架;虚拟GPU主要用于在虚拟机上运营AI、深度学习和高性能计算。
融合了Mellanox 的计算推了DPU的产品。BlueField DPU 通过分流、加速和隔离各种高级网络、存储和安全服务,为云、数据中心或边缘等环境中的各种工作负载提供安全的加速基础设施。BlueField DPU 将计算能力、数据中心基础功能的可编程性及高性能网络相结合,可实现非常高的工作负载。
GPC 2021年推出了基于ARM 架构的面向服务器市场的CPU,用于大型计算中心或者超级计算机等场景中,通过Nvlink 实现CPU、GPU 之间的大带宽链接和交互。未来数据中心将具备 GPU+CPU+DPU 整体解决方案。
4 .国产GPU赛道掀起投资热潮
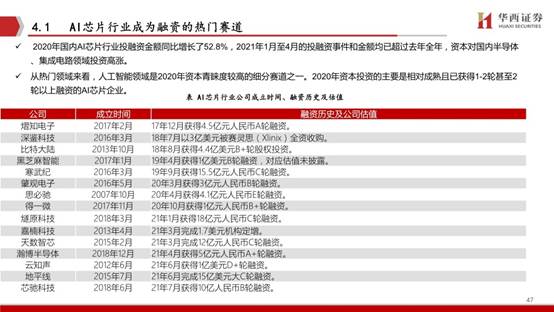
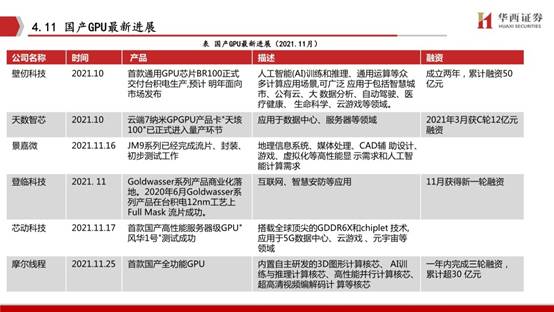
2020年国内AI芯片行业投融资金额同比增长了52.8%,2021年1月至4月的投融资事件和金额均已超过去年全年,资本对国内半导体、集成电路领域投资高涨。
从热门领域来看,人工智能领域是2020年资本青睐度较高的细分赛道之一。2020年资本投资的主要是相对成熟且已获得1-2轮甚至2轮以上融资的AI芯片企业。沐曦集成电路专注于设计具有完全自主知识产权,针对异构计算等各类应用的高性能通用GPU芯片。
公司致力于打造国内最强商用GPU芯片,产品主要应用方向包含传统GPU及移动应用,人工智能、云计算、数据中心等高性能异构计算领域,是今后面向社会各个方面通用信息产业提升算力水平的重要基础产品。
拟采用业界最先进的5nm工艺技术,专注研发全兼容CUDA及ROCm生态的国产高性能GPU芯片,满足HPC、数据中心及AI等方面的计算需求。致力于研发生产拥有自主知识产权的、安全可靠的高性能GPU芯片,服务数据中心、云游戏、人工智能等需要高算力的诸多重要领域。
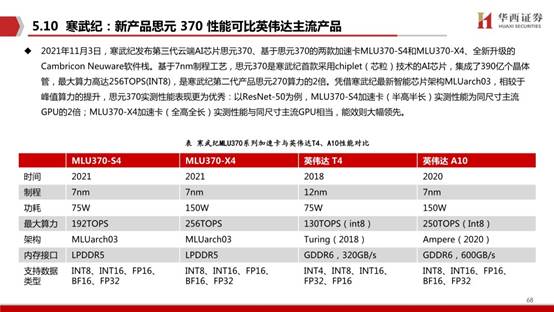
壁仞科技创立于2019年,公司在GPU和DSA(专用加速器)等领域具备丰富的技术储备聚焦于云端通用智能计算,逐步在AI训练和推理、图形渲染、高性能通用计算等多个领域赶超现有解决方案,以实现国产高端通用智能计算芯片的突破。
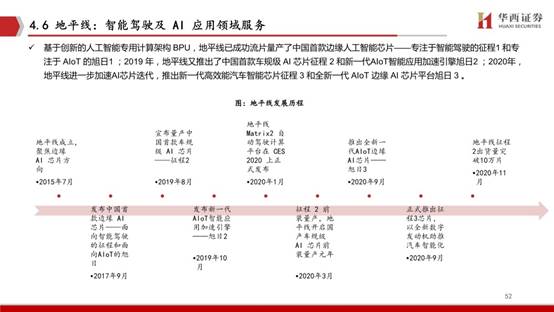
智能物联网需求将使云端计算的负荷成倍增长。智能物联网是未来的趋势所向,海量的碎片化场景与计算旭日处理器强大的边缘计算能力,帮助设备高效处理本地数据。面向AIoT,地平线推出旭日系列边缘 AI 芯片。旭日2采用 BPU 伯努利1.0 架构,可提供 4TOPS 等效算力,旭日3 采用伯努利2.0 ,可提供 5TOPS 的等效算力。
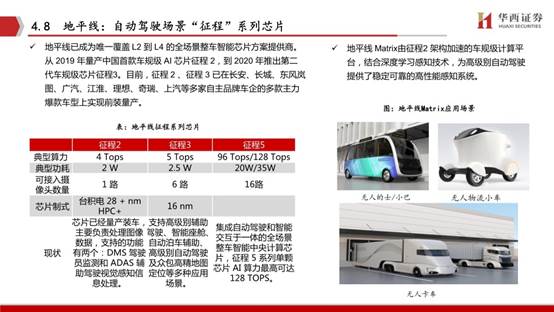
黑芝麻智能科技是一家专注于视觉感知技术与自主IP芯片开发的企业。公司主攻领域为嵌入式图像和计算机视觉,提供基于光控技术、图像处理、计算图像以及人工智能的嵌入式视觉感知芯片计算平台,为ADAS及自动驾驶提供完整的商业落地方案。
基于华山二号 A1000 芯片,黑芝麻提供了四种智能驾驶解决方案。单颗 A1000L 芯片适用于 ADAS 辅助驾驶;单颗 A1000 芯片适用于 L2+ 自动驾驶;双 A1000 芯片互联可达 140TOPS 算力,支持 L3 等级自动驾驶;四颗 A1000 芯片则可以支持 L4 甚至以上的自动驾驶需求。另外,黑芝麻还可以根据不同的客户需求,提供定制化服务。
黑芝麻智能首款芯片与上汽的合作已实现量产,第二款芯片A1000正在量产过程中,预计今年下半年在商用车领域实现10万片量级以上的量产,明年将在乘用车领域量产落地。黑芝麻智能已与一汽、蔚来、上汽、比亚迪、博世、滴滴、中科创达、亚太机电等企业在L2、L3级自动驾驶感知系统解决方案上均有合作。
5 .重点公司分析
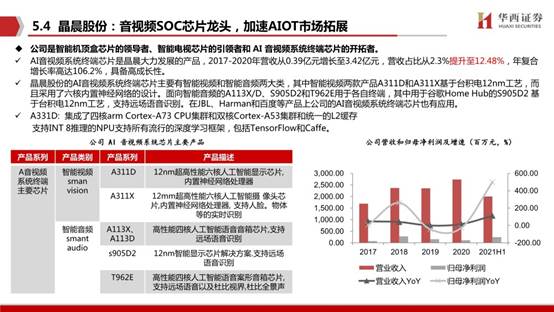
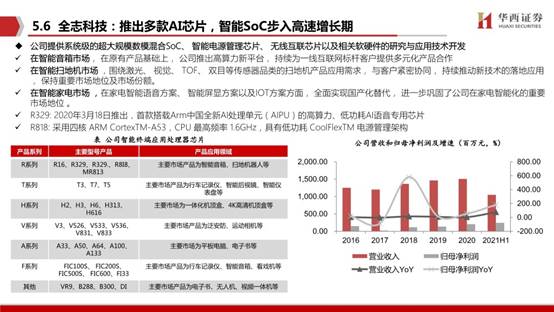
晶晨股份:公司是智能机顶盒芯片的领导者、智能电视芯片的引领者和 AI 音视频系统终端芯片的开拓者。AI音视频系统终端芯片是晶晨大力发展的产品,2017-2020年营收从0.39亿元增长至3.42亿元,营收占比从2.3%提升至12.48%,年复合增长率高达106.2%,具备高成长性。
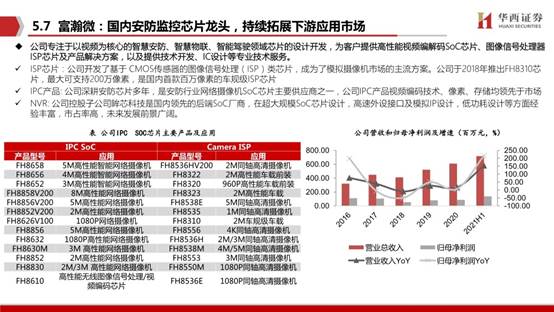
晶晨股份的AI音视频系统终端芯片主要有智能视频和智能音频两大类,其中智能视频两款产品A311D和A311X基于台积电12nm工艺,而且采用了六核内置神经网络的设计。面向智能音频的A113X/D、S905D2和T962E用于各自终端,其中用于谷歌Home Hub的S905D2 基于台积电12nm工艺,支持远场语音识别。在JBL、Harman和百度等产品上公司的AI音视频系统终端芯片也有应用。
报告节选:































 京公网安备 11010802036102号北京金支点技术服务有限公司保留所有权利 | Copyright © 2005-2026 Beijing Golden Point Outsourcing Service Co., Ltd. All Rights Reserved.
京公网安备 11010802036102号北京金支点技术服务有限公司保留所有权利 | Copyright © 2005-2026 Beijing Golden Point Outsourcing Service Co., Ltd. All Rights Reserved.